
排序习题
【模板】排序
题目描述
将读入的 $N$ 个数从小到大排序后输出。
输入格式
第一行为一个正整数 $N$。
第二行包含 $N$ 个空格隔开的正整数 $a_i$,为你需要进行排序的数。
输出格式
将给定的 $N$ 个数从小到大输出,数之间空格隔开,行末换行且无空格。
样例 #1
样例输入 #1
1 | 5 |
样例输出 #1
1 | 1 2 4 4 5 |
提示
对于 $20\%$ 的数据,有 $1 \leq N \leq 10^3$;
对于 $100\%$ 的数据,有 $1 \leq N \leq 10^5$,$1 \le a_i \le 10^9$。
题解
思路
代码
1 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
using namespace std;
int main() {
// 读入N
int N;
cin >> N;
// 读入N个数并存储在vector中
vector<int> numbers(N);
for (int i = 0; i < N; ++i) {
cin >> numbers[i];
}
// 使用sort函数对vector进行排序
sort(numbers.begin(), numbers.end());
// 输出排序后的数
for (int i = 0; i < N; ++i) {
cout << numbers[i];
if (i != N - 1) {
cout << " ";
}
}
cout << endl;
return 0;
}
1 |
|
[NOIP2006 普及组] 明明的随机数
题目描述
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了 $N$ 个 $1$ 到 $1000$ 之间的随机整数 $(N\leq100)$,对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作。
输入格式
输入有两行,第 $1$ 行为 $1$ 个正整数,表示所生成的随机数的个数 $N$。
第 $2$ 行有 $N$ 个用空格隔开的正整数,为所产生的随机数。
输出格式
输出也是两行,第 $1$ 行为 $1$ 个正整数 $M$,表示不相同的随机数的个数。
第 $2$ 行为 $M$ 个用空格隔开的正整数,为从小到大排好序的不相同的随机数。
样例 #1
样例输入 #1
1 | 10 |
样例输出 #1
1 | 8 |
提示
NOIP 2006 普及组 第一题
题解
思路
这道题需要去重和排序,排序可以使用桶排序或者sort函数直接排序,然后去重的方法是将数组中当前所指的数与前一个不同就输出这个数,如果相同就不输出。
代码
1 |
|
[NOIP2009 普及组] 分数线划定
题目描述
世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A 市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试。面试分数线根据计划录取人数的 $150\%$ 划定,即如果计划录取 $m$ 名志愿者,则面试分数线为排名第 $m \times 150\%$(向下取整)名的选手的分数,而最终进入面试的选手为笔试成绩不低于面试分数线的所有选手。
现在就请你编写程序划定面试分数线,并输出所有进入面试的选手的报名号和笔试成绩。
输入格式
第一行,两个整数 $n,m(5 \leq n \leq 5000,3 \leq m \leq n)$,中间用一个空格隔开,其中 $n$ 表示报名参加笔试的选手总数,$m$ 表示计划录取的志愿者人数。输入数据保证 $m \times 150\%$ 向下取整后小于等于 $n$。
第二行到第 $n+1$ 行,每行包括两个整数,中间用一个空格隔开,分别是选手的报名号 $k(1000 \leq k \leq 9999)$和该选手的笔试成绩 $s(1 \leq s \leq 100)$。数据保证选手的报名号各不相同。
输出格式
第一行,有 $2$ 个整数,用一个空格隔开,第一个整数表示面试分数线;第二个整数为进入面试的选手的实际人数。
从第二行开始,每行包含 $2$ 个整数,中间用一个空格隔开,分别表示进入面试的选手的报名号和笔试成绩,按照笔试成绩从高到低输出,如果成绩相同,则按报名号由小到大的顺序输出。
样例 #1
样例输入 #1
1 | 6 3 |
样例输出 #1
1 | 88 5 |
提示
【样例说明】
$m \times 150\% = 3 \times150\% = 4.5$,向下取整后为 $4$。保证 $4$ 个人进入面试的分数线为 $88$,但因为 $88$ 有重分,所以所有成绩大于等于 $88$ 的选手都可以进入面试,故最终有 $5$ 个人进入面试。
NOIP 2009 普及组 第二题
题解
思路
报名号和笔试成绩需要一起排序,这里快排用sort函数,关键在于用结构体数组去调用报名号和笔试成绩,然后用bool类型去判断条件,让成绩从高到低排,如果成绩相同就将按报名号从低到高排序。然后用sort函数根据这个条件去排序。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
using namespace std;
struct people{
int k,s;
};
people mem[5000];
bool cmp(people x,people y){
if(x.s>y.s) return 1;
if(x.s==y.s&&x.k<y.k) return 1;
return 0;
}
int main() {
int n,m,pass,a=0;
cin>>n>>m;
for(int i=0;i<n;i++){
cin>>mem[i].k>>mem[i].s;
}
sort(mem,mem+n,cmp);
pass=mem[m*3/2-1].s;
for(int i=0;i<n;i++){
if(mem[i].s>=pass) a++;
}
cout<<pass<<" "<<a<<endl;
for(int i=0;i<a;i++){
cout<<mem[i].k<<" "<<mem[i].s<<endl;
}
return 0;
}
1 |
|
[NOIP2005 提高组] 谁拿了最多奖学金
题目描述
某校的惯例是在每学期的期末考试之后发放奖学金。发放的奖学金共有五种,获取的条件各自不同:
- 院士奖学金,每人 $8000$ 元,期末平均成绩高于 $80$ 分($>80$),并且在本学期内发表$1$篇或$1$篇以上论文的学生均可获得;
- 五四奖学金,每人 $4000$ 元,期末平均成绩高于 $85$ 分($>85$),并且班级评议成绩高于 $80$ 分($>80$)的学生均可获得;
- 成绩优秀奖,每人 $2000$ 元,期末平均成绩高于 $90$ 分($>90$)的学生均可获得;
- 西部奖学金,每人 $1000$ 元,期末平均成绩高于 $85$ 分($>85$)的西部省份学生均可获得;
- 班级贡献奖,每人 $850$ 元,班级评议成绩高于 $80$ 分($>80$)的学生干部均可获得;
只要符合条件就可以得奖,每项奖学金的获奖人数没有限制,每名学生也可以同时获得多项奖学金。例如姚林的期末平均成绩是 $87$ 分,班级评议成绩 $82$ 分,同时他还是一位学生干部,那么他可以同时获得五四奖学金和班级贡献奖,奖金总数是 $4850$ 元。
现在给出若干学生的相关数据,请计算哪些同学获得的奖金总数最高(假设总有同学能满足获得奖学金的条件)。
输入格式
第一行是$1$个整数 $N$,表示学生的总数。
接下来的 $N$ 行每行是一位学生的数据,从左向右依次是姓名,期末平均成绩,班级评议成绩,是否是学生干部,是否是西部省份学生,以及发表的论文数。姓名是由大小写英文字母组成的长度不超过 $20$ 的字符串(不含空格);期末平均成绩和班级评议成绩都是 $0$ 到 $100$ 之间的整数(包括 $0$ 和 $100$);是否是学生干部和是否是西部省份学生分别用 $1$ 个字符表示,$\tt Y$ 表示是,$\tt N$ 表示不是;发表的论文数是 $0$ 到 $10$ 的整数(包括 $0$ 和 $10$)。每两个相邻数据项之间用一个空格分隔。
输出格式
共 $3$ 行。
- 第 $1$ 行是获得最多奖金的学生的姓名。如果有两位或两位以上的学生获得的奖金最多,输出他们之中在输入文件中出现最早的学生的姓名。
- 第 $2$ 行是这名学生获得的奖金总数。
- 第 $3$ 行是这 $N$ 个学生获得的奖学金的总数。
样例 #1
样例输入 #1
1 | 4 |
样例输出 #1
1 | ChenRuiyi |
提示
【数据范围】
对于 $100\%$ 的数据,满足 $1 \le N \le 100$。
【题目来源】
NOIP 2005 提高组第一题
题解
思路
利用结构体和sort函数进行排序。结构体来调用姓名,期末平均成绩,班级评议成绩,是否是学生干部,是否是西部省份学生,以及发表的论文数。然后对每个人的奖学金进行排序,当奖学金相同时则按照他们出现最早的名字排序。
代码
1 |
|
[NOIP2011 普及组] 瑞士轮
题目背景
在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。后者的特点是较为公平,偶然性较低,但比赛过程往往十分冗长。
本题中介绍的瑞士轮赛制,因最早使用于$1895$年在瑞士举办的国际象棋比赛而得名。它可以看作是淘汰赛与循环赛的折中,既保证了比赛的稳定性,又能使赛程不至于过长。
题目描述
$2 \times N$ 名编号为 $1\sim 2N$ 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第$1$ 名和第$2$ 名、第 $3$ 名和第 $4$名、……、第$2K - 1 $名和第$ 2K$名、…… 、第$2N - 1 $名和第$2N$名,各进行一场比赛。每场比赛胜者得$1 $分,负者得 $0 $分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第$ Q$ 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入格式
第一行是三个正整数$N,R ,Q$,每两个数之间用一个空格隔开,表示有 $2 \times N $名选手、$R$ 轮比赛,以及我们关心的名次 $Q$。
第二行是$2 \times N$ 个非负整数$s1, s_2, …, s{2N}$,每两个数之间用一个空格隔开,其中$ si $表示编号为$i$ 的选手的初始分数。 第三行是$2 \times N$ 个正整数$w_1 , w_2 , …, w{2N}$,每两个数之间用一个空格隔开,其中 $w_i$ 表示编号为$i$ 的选手的实力值。
输出格式
一个整数,即$R$ 轮比赛结束后,排名第$ Q$ 的选手的编号。
样例 #1
样例输入 #1
1 | 2 4 2 |
样例输出 #1
1 | 1 |
提示
【样例解释】
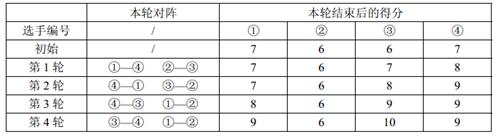
【数据范围】
对于$30\% $的数据,$1 ≤ N ≤ 100$;
对于$50\% $的数据,$1 ≤ N ≤ 10,000 $;
对于$100\%$的数据,$1 ≤ N ≤ 100,000,1 ≤ R ≤ 50,1 ≤ Q ≤ 2N,0 ≤ s1, s_2, …, s{2N}≤10^8,1 ≤w1, w_2 , …, w{2N}≤ 10^8$。
noip2011普及组第3题。
题解
思路
利用归并排序来处理。
代码
1 | // 30分自己写的 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
using namespace std;
typedef struct Node{
int grade;
int num;
}Node;
Node a[maxn];
Node A[100001];
Node B[100001];
int w[maxn];
bool cmp(Node a,Node b)
{
if(a.grade == b.grade)
return a.num<b.num;
return a.grade>b.grade;
}
int n,r,q;
void MergeSort()///把AB归并到a中
{
int i=1,j=1,k=1;///分别用来在AB以及a中移动的指针
while(i<=n && j<=n)
{
if(A[i].grade > B[j].grade || (A[i].grade == B[j].grade && A[i].num < B[j].num))
{
a[k].grade = A[i].grade;
a[k++].num = A[i++].num;
}
else{
a[k].grade = B[j].grade;
a[k++].num = B[j++].num;
}
}
while(i<=n)
{
a[k].grade = A[i].grade;
a[k++].num = A[i++].num;
}
while(j<=n)
{
a[k].grade = B[j].grade;
a[k++].num = B[j++].num;
}
}
int main()
{
cin>>n>>r>>q;///2*n名选手 r轮比赛 关心的名次q
for(int i=1;i<=2*n;i++)
{
cin>>a[i].grade;
a[i].num=i;
}
for(int i=1;i<=2*n;i++)
cin>>w[i];
sort(a+1,a+1+2*n,cmp);
for(int k=1;k<=r;k++)
{
int tt=1;
for(int i=1;i<2*n;i+=2)
{
//cout<<w[a[i].num]<<" "<<w[a[i+1].num]<<endl;
if(w[a[i].num]>w[a[i+1].num])
{
A[tt].grade = a[i].grade+1;
A[tt].num = a[i].num;
B[tt].grade = a[i+1].grade;
B[tt].num = a[i+1].num;
tt++;
} //a[i].grade++;
else
{
A[tt].grade = a[i+1].grade+1;
A[tt].num = a[i+1].num;
B[tt].grade = a[i].grade;
B[tt].num = a[i].num;
tt++;
}
}
MergeSort();
}
cout<<a[q].num<<endl;///排名第q的选手的编号
return 0;
}
1 |
|
逆序对
题目描述
猫猫 TOM 和小老鼠 JERRY 最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计。
最近,TOM 老猫查阅到一个人类称之为“逆序对”的东西,这东西是这样定义的:对于给定的一段正整数序列,逆序对就是序列中 $a_i>a_j$ 且 $i<j$ 的有序对。知道这概念后,他们就比赛谁先算出给定的一段正整数序列中逆序对的数目。注意序列中可能有重复数字。
Update:数据已加强。
输入格式
第一行,一个数 $n$,表示序列中有 $n$个数。
第二行 $n$ 个数,表示给定的序列。序列中每个数字不超过 $10^9$。
输出格式
输出序列中逆序对的数目。
样例 #1
样例输入 #1
1 | 6 |
样例输出 #1
1 | 11 |
提示
对于 $25\%$ 的数据,$n \leq 2500$
对于 $50\%$ 的数据,$n \leq 4 \times 10^4$。
对于所有数据,$n \leq 5 \times 10^5$
请使用较快的输入输出
应该不会 $O(n^2)$ 过 50 万吧 by chen_zhe
题解
思路
利用归并排序,将数组先分成两部分,然后去比较大小,再将小的数放到临时数组中,最后排完序后将临时数组赋给原来的数组。同时在比较的过程中如果满足逆序对的话,就让一个标识变量+1用来记录逆序对的个数。
代码
1 |
|



